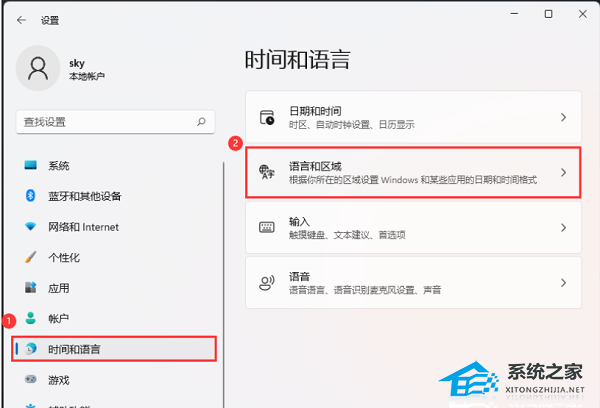
一、去掉相邻重复的数据行
代码如下:
$cat data1.txt | uniq
输出:
beijing
wuhan
beijing
wuhan
二、去掉所有重复的数据行
代码如下:
$cat data1.txt | sort | uniq
注:
只有uniq命令的话,只是把相邻的重复的数据行去掉。
如果先 sort 的话,就会把所有重复的数据行变成相邻的数据行,再 uniq 的话,就去掉所有重复的数据行了。
输出:
beijing
wuhan
附:data1.txt
代码如下:
[root@syy ~]# cat data1.txt
beijing
beijing
wuhan
wuhan
wuhan
beijing
beijing
beijing
wuhan
wuhan
注:在过滤日志中的IP地址很有用。
Linux下删除大数据文件中部分字段重复的行
最近写的一个数据采集程序生成了一个含有1千多万行数据的文件,数据由4个字段组成,按照要求需要删除第二个字段重复的行,找来找去linux下也没找到合适的工具,sed/gawk等流处理工具只能针对一行一行处理,并无法找到字段重复的行。看来只好自己python一个程序了,突然想起来利用mysql,于是进行乾坤大挪移:
1. 利用mysqlimport --local dbname data.txt导入数据到表中,表名要与文件名一致
2. 执行下列sql语句(要求唯一的字段为uniqfield)
代码如下:
use dbname;
alter table tablename add rowid int auto_increment not null;
create table t select min(rowid) as rowid from tablename group by uniqfield;
create table t2 select tablename .* from tablename,t where tablename.rowid= t.rowid;《/p》 《p》drop table tablename;
rename table t2 to tablename;
上面就是Linux删除文件重复数据行的方法介绍了,本文介绍了多种情况下删除文件重复数据行的方法,希望对你有所帮助。
一、去掉相邻重复的数据行
代码如下:
$cat data1.txt | uniq
输出:
beijing
wuhan
beijing
wuhan
二、去掉所有重复的数据行
代码如下:
$cat data1.txt | sort | uniq
注:
只有uniq命令的话,只是把相邻的重复的数据行去掉。
如果先 sort 的话,就会把所有重复的数据行变成相邻的数据行,再 uniq 的话,就去掉所有重复的数据行了。
输出:
beijing
wuhan
附:data1.txt
代码如下:
[root@syy ~]# cat data1.txt
beijing
beijing
wuhan
wuhan
wuhan
beijing
beijing
beijing
wuhan
wuhan
注:在过滤日志中的IP地址很有用。
Linux下删除大数据文件中部分字段重复的行
最近写的一个数据采集程序生成了一个含有1千多万行数据的文件,数据由4个字段组成,按照要求需要删除第二个字段重复的行,找来找去linux下也没找到合适的工具,sed/gawk等流处理工具只能针对一行一行处理,并无法找到字段重复的行。看来只好自己python一个程序了,突然想起来利用mysql,于是进行乾坤大挪移:
1. 利用mysqlimport --local dbname data.txt导入数据到表中,表名要与文件名一致
2. 执行下列sql语句(要求唯一的字段为uniqfield)
代码如下:
use dbname;
alter table tablename add rowid int auto_increment not null;
create table t select min(rowid) as rowid from tablename group by uniqfield;
create table t2 select tablename .* from tablename,t where tablename.rowid= t.rowid;《/p》 《p》drop table tablename;
rename table t2 to tablename;
上面就是Linux删除文件重复数据行的方法介绍了,本文介绍了多种情况下删除文件重复数据行的方法,希望对你有所帮助。
Linux系统操作中,如果文件中的数据过多,想要删除重复数据行是非常麻烦的,查找不方便,那么有什么方法能够快速删除文件重复数据行呢?下面小编就给大家介绍下如何删除文件重复数据行,一起来看看吧。
一、去掉相邻重复的数据行
代码如下:
$cat data1.txt | uniq
输出:
beijing
wuhan
beijing
wuhan
二、去掉所有重复的数据行
代码如下:
$cat data1.txt | sort | uniq
注:
只有uniq命令的话,只是把相邻的重复的数据行去掉。
如果先 sort 的话,就会把所有重复的数据行变成相邻的数据行,再 uniq 的话,就去掉所有重复的数据行了。
输出:
beijing
wuhan
附:data1.txt
代码如下:
[root@syy ~]# cat data1.txt
beijing
beijing
wuhan
wuhan
wuhan
beijing
beijing
beijing
wuhan
wuhan
注:在过滤日志中的IP地址很有用。
Linux下删除大数据文件中部分字段重复的行
最近写的一个数据采集程序生成了一个含有1千多万行数据的文件,数据由4个字段组成,按照要求需要删除第二个字段重复的行,找来找去linux下也没找到合适的工具,sed/gawk等流处理工具只能针对一行一行处理,并无法找到字段重复的行。看来只好自己python一个程序了,突然想起来利用mysql,于是进行乾坤大挪移:
1. 利用mysqlimport --local dbname data.txt导入数据到表中,表名要与文件名一致
2. 执行下列sql语句(要求唯一的字段为uniqfield)
代码如下:
use dbname;
alter table tablename add rowid int auto_increment not null;
create table t select min(rowid) as rowid from tablename group by uniqfield;
create table t2 select tablename .* from tablename,t where tablename.rowid= t.rowid;《/p》 《p》drop table tablename;
rename table t2 to tablename;
上面就是Linux删除文件重复数据行的方法介绍了,本文介绍了多种情况下删除文件重复数据行的方法,希望对你有所帮助。
一、去掉相邻重复的数据行
代码如下:
$cat data1.txt | uniq
输出:
beijing
wuhan
beijing
wuhan
二、去掉所有重复的数据行
代码如下:
$cat data1.txt | sort | uniq
注:
只有uniq命令的话,只是把相邻的重复的数据行去掉。
如果先 sort 的话,就会把所有重复的数据行变成相邻的数据行,再 uniq 的话,就去掉所有重复的数据行了。
输出:
beijing
wuhan
附:data1.txt
代码如下:
[root@syy ~]# cat data1.txt
beijing
beijing
wuhan
wuhan
wuhan
beijing
beijing
beijing
wuhan
wuhan
注:在过滤日志中的IP地址很有用。
Linux下删除大数据文件中部分字段重复的行
最近写的一个数据采集程序生成了一个含有1千多万行数据的文件,数据由4个字段组成,按照要求需要删除第二个字段重复的行,找来找去linux下也没找到合适的工具,sed/gawk等流处理工具只能针对一行一行处理,并无法找到字段重复的行。看来只好自己python一个程序了,突然想起来利用mysql,于是进行乾坤大挪移:
1. 利用mysqlimport --local dbname data.txt导入数据到表中,表名要与文件名一致
2. 执行下列sql语句(要求唯一的字段为uniqfield)
代码如下:
use dbname;
alter table tablename add rowid int auto_increment not null;
create table t select min(rowid) as rowid from tablename group by uniqfield;
create table t2 select tablename .* from tablename,t where tablename.rowid= t.rowid;《/p》 《p》drop table tablename;
rename table t2 to tablename;
上面就是Linux删除文件重复数据行的方法介绍了,本文介绍了多种情况下删除文件重复数据行的方法,希望对你有所帮助。
1、如非特殊说明,本站对提供的源码不拥有任何权利,其版权归原著者拥有。
2、本网站所有源码和软件均为作者提供和网友推荐收集整理而来,仅供学习和研究使用。
3、如有侵犯你版权的,请来信(邮箱:123456@qq.com)指出,核实后,本站将立即改正。